Excel “Filter and Edit” - Demonstrated in Pandas
Posted by Chris Moffitt in articles

Introduction
I have heard from various people that my previous articles on common Excel tasks in pandas were useful in helping new pandas users translate Excel processes into equivalent pandas code. This article will continue that tradition by illustrating various pandas indexing examples using Excel’s Filter function as a model for understanding the process.
One of the first things most new pandas users learn is basic data filtering. Despite working with pandas over the past few months, I recently realized that there was another benefit to the pandas filtering approach that I was not using in my day to day work. Namely that you can filter on a given set of columns but update another set of columns using a simplified pandas syntax. This is similar to what I’ll call the “Filter and Edit” process in Excel.
This article will walk through some examples of filtering a pandas DataFrame and
updating the data based on various criteria. Along the way, I will explain some
more about panda’s indexing and how to use indexing methods such as
.loc
and
.iloc
to quickly and easily update a subset of data based on
simple or complex criteria.
Excel: “Filter and Edit”
Outside of the Pivot Table, one of the top go-to tools in Excel is the Filter. This simple tool allows a user to quickly filter and sort the data by various numeric, text and formatting criteria. Here is a basic screenshot of some sample data with data filtered by several different criteria:
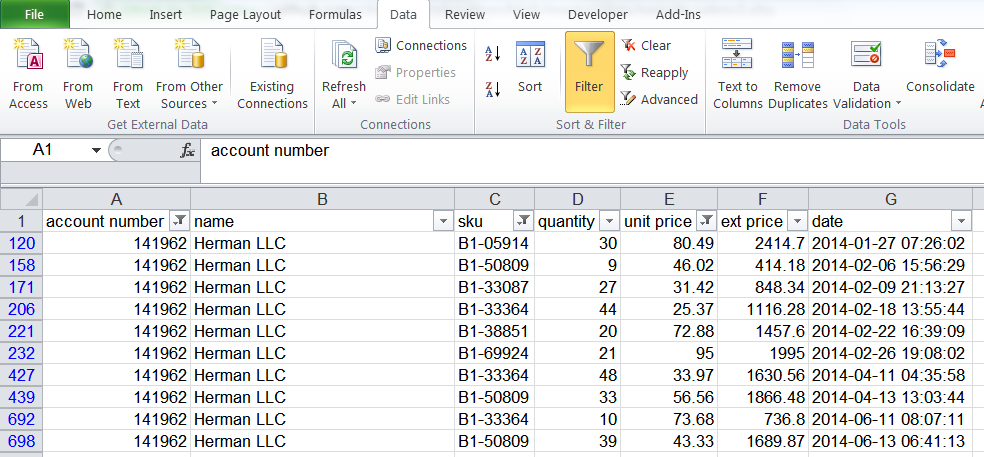
The Filter process is intuitive and is easy to grasp for even the most novice Excel user. I have also noticed that people will use this feature to select rows of data, then update additional columns based on the row criteria. The example below shows what I’m describing:
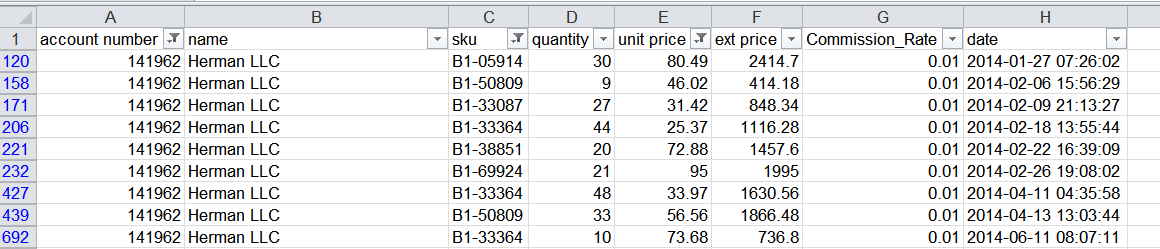
In the example, I have filtered the data on Account Number, SKU and Unit Price. Then I manually added a Commission_Rate column and typed in 0.01 in each cell. The benefit to this approach is that it is easy to understand and can help someone manage relatively complex data without writing long Excel formulas or getting into VBA. The downside of this approach is that it is not repeatable and can be difficult for someone from the outside to understand which criteria were used for any filter.
For instance, if you look at the screenshot about, there is no obvious way to tell what is filtered without looking at each column. Fortunately, we can do something very similar in pandas. Not surprisingly, it is easy in pandas to execute this “Filter and Edit” model with simple and clean code.
Boolean Indexing
Now that you have a feel for the problem, I want to step through some details of boolean indexing in pandas. This is an important concept to understand if you want to understand pandas’ Indexing and Selecting of Data in the most broad sense. This idea may seem a little complex to the new pandas user (and maybe too basic for experienced users) but I think it is important to take some time and understand it. If you grasp this concept, the basic process of working with data in pandas will be more straightforward.
Pandas supports indexing (or selecting data) by using labels, position based integers or a list of boolean values (True/False). Using a list of boolean values to select a row is called boolean indexing and will be the focus of the rest of this article.
I find that my pandas workflow tends to focus mostly on using lists of boolean values for selecting my data. In other words, when I create pandas DataFrames, I tend to keep the default index in the DataFrame. Therefore the index is not really meaningful on its own and not straightforward for selecting data.
Let’s look at some example DataFrames to help clarify the what a boolean index in pandas does.
First, we will create a very small DataFrame purely from a python list and use it to show how boolean indexing works.
import pandas as pd
sales = [('account', ['Jones LLC', 'Alpha Co', 'Blue Inc', 'Mega Corp']),
('Total Sales', [150, 200, 75, 300]),
('Country', ['US', 'UK', 'US', 'US'])]
df = pd.DataFrame.from_items(sales)
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 1 | Alpha Co | 200 | UK |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
Notice how the values 0-3, get automatically assigned to the rows? Those are the indices and they are not particularly meaningful in this data set but are useful to pandas and are important to understand for other use cases not described below.
When we refer to boolean indexing, we simply mean that we can pass in a list of
True
or
False
values representing each row we want to view.
In this case, if we want to view the data for Jones LLC, Blue Inc and Mega Corp,
we can see that the
True
False
list would look like this:
indices = [True, False, True, True]
It should be no surprise, that you can pass this list to your DataFrame and it
will only display the rows where our value is
True
:
df[indices]
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
Here is a visual of what just happened:
This manual list creation of the index works but obviously is not scaleable or very useful for anything more than a trivial data set. Fortunately pandas makes it very easy to create these boolean indexes using a simple query language that should be familiar to someone that has used python (or any language for that matter).
For an example, let’s look at all sales lines from the US. If we execute a python expression based on the Country column:
df.Country == 'US'
0 True 1 False 2 True 3 True Name: Country, dtype: bool
The example shows how pandas will take your traditional python logic, apply it to a DataFrame and return a list of boolean values. This list of boolean values can then be passed to the DataFrame to get the corresponding rows of data.
In real code, you would not do this two step process. The shorthand method for doing this would typically look like this:
df[df["Country"] == 'US']
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
While this concept is simple, you can write fairly complex logic to filter your data using the power of python.
df[df.Country == 'US']
is equivalent to
df[df["Country"] == 'US']
The ‘.’ notation is cleaner but will not work when there are spaces in your column names.Selecting the Columns
Now that we have figured out how to select rows of data, how can we control which
columns to display? In the example above, there’s no obvious way to do that. Pandas
can support this use case using three types of location based indexing:
.loc
,
iloc
,
and
.ix
. These functions also allow us to select columns in addition to the
row selection we have seen so far.
.ix
function is longer supported. It should not be used.There is a lot of confusion about when to use
.loc
,
iloc
, or
.ix
.
The quick summary of the difference is that:
.locis used for label indexing.ilocis used for position based integers.ixis a shortcut that will try to use labels (like.loc) but will fall back to position based integers (like.iloc)
So, the question is, which one should I use? I will profess that I get tripped up some times
on this one too. I have found that I use
.loc
most frequently. Mainly because
my data does not lend itself to meaningful position based indexing (in other words,
I rarely find myself needing
.iloc
) so I stick with
.loc
.
To be fair each of these methods do have their place and are useful in many situations. One area in particular is when dealing with MultiIndex DataFrames. I will not cover that topic in this article - maybe in a future post.
Now that we have covered this topic, let’s show how to filter a DataFrame on values in a row and select specific columns to display.
Continuing with our example, what if we just want to show the account names that
correspond to our index? Using
.loc
it is simple:
df.loc[[True, True, False, True], "account"]
1 Alpha Co 2 Blue Inc 3 Mega Corp Name: account, dtype: object
If you would like to see multiple columns, just pass a list:
df.loc[[True, True, False, True], ["account", "Country"]]
| account | Country | |
|---|---|---|
| 0 | Jones LLC | US |
| 1 | Alpha Co | UK |
| 3 | Mega Corp | US |
The real power is when you create more complex queries on your data. In this case, let’s show all account names and Countries where sales > 200:
df.loc[df["Total Sales"] > 200, ["account", "Country"]]
| account | Country | |
|---|---|---|
| 3 | Mega Corp | US |
This process can be thought of somewhat equivalent to Excel’s Filter we discussed above. You have the added benefit that you can also limit the number of columns you retrieve, not just the rows.
Editing Columns
All of this is good background but where this process really shines is when you use a similar approach for updating one or more columns based on a row selection.
For one simple example, let’s add a commission rate column to our data:
df["rate"] = 0.02
| account | Total Sales | Country | rate | |
|---|---|---|---|---|
| 0 | Jones LLC | 150 | US | 0.02 |
| 1 | Alpha Co | 200 | UK | 0.02 |
| 2 | Blue Inc | 75 | US | 0.02 |
| 3 | Mega Corp | 300 | US | 0.02 |
Let’s say that if you sold more than 100, your rate is 5%. The basic process is to setup a boolean index to select the columns, then assign the value to the rate column:
df.loc[df["Total Sales"] > 100, ["rate"]] = .05
| account | Total Sales | Country | rate | |
|---|---|---|---|---|
| 0 | Jones LLC | 150 | US | 0.05 |
| 1 | Alpha Co | 200 | UK | 0.05 |
| 2 | Blue Inc | 75 | US | 0.02 |
| 3 | Mega Corp | 300 | US | 0.05 |
Hopefully if you stepped through this article, this will make sense and that it will help you understand how this syntax works. Now you have the fundamentals of the “Filter and Edit” approach. The final section will show this process in a little more detail in Excel and pandas.
Bringing It All Together
For the final example, we will create a simple commissions calculator using the following rules:
- All commissions calculated at the transaction level
- Base commission on all sales is 2%
- All shirts will get a commission of 2.5%
- A special program is going on where selling > 10 belts in one transaction gets 4% commission
- There is a special bonus of $250 plus a 4.5% commission for all shoe sales > $1000 in a single transaction
In order to do this in Excel, using the Filter and edit approach:
- Add a commission column with 2%
- Add a bonus column of $0
- Filter on shirts and change the vale to 2.5%
- Clear the filter
- Filter for belts and quantity > 10 and change the value to 4%
- Clear the filter
- Filter for shoes > $1000 and add commission and bonus values of 4.5% and $250 respectively
I am not going to show a screen shot of each step but here is the last filter:
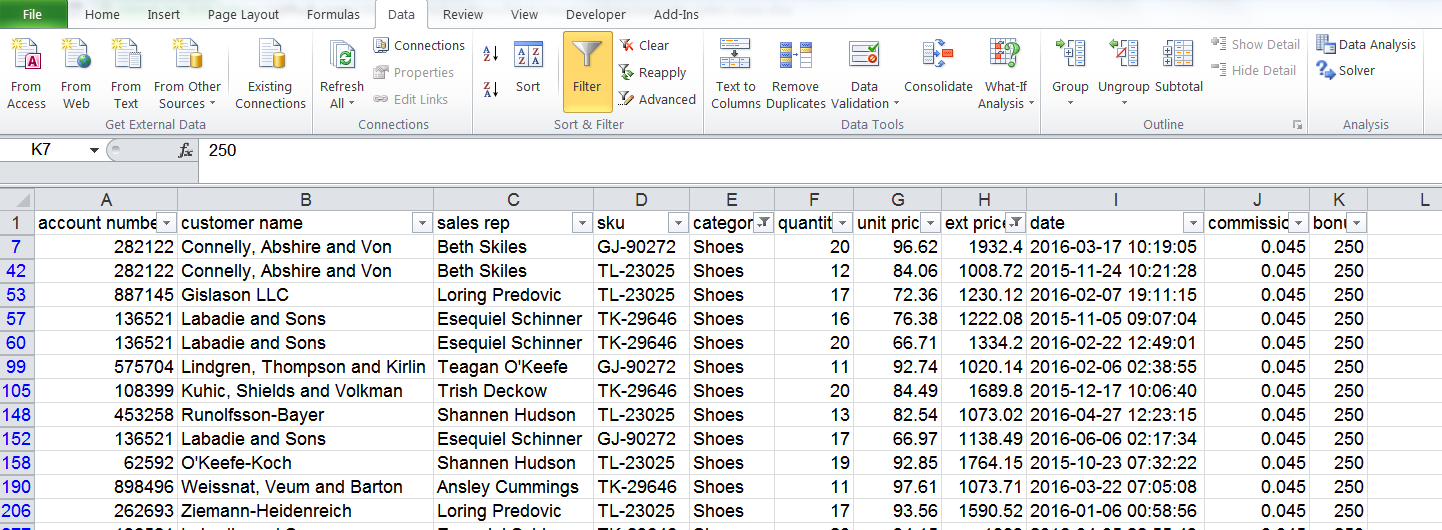
This approach is simple enough to manipulate in Excel but it is not very repeatable nor audit-able. There are certainly other approaches to accomplish this in Excel - such as formulas or VBA. However, this Filter and Edit approach is common and is illustrative of the pandas logic.
Now, let’s walk through the whole example in pandas.
First, read in the Excel file and add a column with the 2% default rate:
import pandas as pd
df = pd.read_excel("https://github.com/chris1610/pbpython/blob/master/data/sample-sales-reps.xlsx?raw=true")
df["commission"] = .02
df.head()
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 680916 | Mueller and Sons | Loring Predovic | GP-14407 | Belt | 19 | 88.49 | 1681.31 | 2015-11-17 05:58:34 | 0.02 |
| 1 | 680916 | Mueller and Sons | Loring Predovic | FI-01804 | Shirt | 3 | 78.07 | 234.21 | 2016-02-13 04:04:11 | 0.02 |
| 2 | 530925 | Purdy and Sons | Teagan O’Keefe | EO-54210 | Shirt | 19 | 30.21 | 573.99 | 2015-08-11 12:44:38 | 0.02 |
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.02 |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.02 |
The next commission rule is for all shirts to get 2.5% and Belt sales > 10 get a 4% rate:
df.loc[df["category"] == "Shirt", ["commission"]] = .025
df.loc[(df["category"] == "Belt") & (df["quantity"] >= 10), ["commission"]] = .04
df.head()
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 680916 | Mueller and Sons | Loring Predovic | GP-14407 | Belt | 19 | 88.49 | 1681.31 | 2015-11-17 05:58:34 | 0.040 |
| 1 | 680916 | Mueller and Sons | Loring Predovic | FI-01804 | Shirt | 3 | 78.07 | 234.21 | 2016-02-13 04:04:11 | 0.025 |
| 2 | 530925 | Purdy and Sons | Teagan O’Keefe | EO-54210 | Shirt | 19 | 30.21 | 573.99 | 2015-08-11 12:44:38 | 0.025 |
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.025 |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.025 |
The final commission rule is to add the special bonus:
df["bonus"] = 0
df.loc[(df["category"] == "Shoes") & (df["ext price"] >= 1000 ), ["bonus", "commission"]] = 250, 0.045
# Display a sample of rows that show this bonus
df.ix[3:7]
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | bonus | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.025 | 0 |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.025 | 0 |
| 5 | 282122 | Connelly, Abshire and Von | Beth Skiles | GJ-90272 | Shoes | 20 | 96.62 | 1932.40 | 2016-03-17 10:19:05 | 0.045 | 250 |
| 6 | 398620 | Brekke Ltd | Esequiel Schinner | DU-87462 | Shirt | 10 | 67.64 | 676.40 | 2015-11-25 22:05:36 | 0.025 | 0 |
| 7 | 218667 | Jaskolski-O’Hara | Trish Deckow | DU-87462 | Shirt | 11 | 91.86 | 1010.46 | 2016-04-24 15:05:58 | 0.025 | 0 |
In order to do the commissions calculation:
# Calculate the compensation for each row
df["comp"] = df["commission"] * df["ext price"] + df["bonus"]
# Summarize and round the results by sales rep
df.groupby(["sales rep"])["comp"].sum().round(2)
sales rep Ansley Cummings 2169.76 Beth Skiles 3028.60 Esequiel Schinner 10451.21 Loring Predovic 10108.60 Shannen Hudson 5275.66 Teagan O'Keefe 7989.52 Trish Deckow 5807.74 Name: comp, dtype: float64
If you are interested, an example notebook is hosted on github.
Conclusion
Thanks for reading through the article. I find that one of the biggest challenges for new users in learning how to use pandas is figuring out how to use their Excel-based knowledge to build an equivalent pandas-based solution. In many cases the pandas solution is going to be more robust, faster, easier to audit and more powerful. However, the learning curve can take some time. I hope that this example showing how to solve a problem using Excel’s Filter tool will be a useful guide for those just starting on this pandas journey. Good luck!
Changes
- 29-August-2020: Noted that
.ixis deprecated and should not be used at all.
Comments