Introduction to Polars
Posted by Chris Moffitt in articles

Introduction
It’s been a while since I’ve posted anything on the blog. One of the primary reasons for the hiatus is that I have been using python and pandas but not to do anything very new or different.
In order to shake things up and hopefully get back into the blog a bit, I’m going to write about polars. This article assumes you know how to use pandas and are interested in determining if polars can fit into your workflow. I will cover some basic polars concepts that should get you started on your journey.
Along the way I will point out some of the things I liked and some of the differences that that might limit your usage of polars if you’re coming from pandas.
Ultimately, I do like polars and what it is trying to do. I’m not ready to throw out all my pandas code and move over to polars. However, I can see where polars could fit into my toolkit and provide some performance and capability that is missing from pandas.
As you evaluate the choice for yourself, it is important to try other frameworks and tools and evaluate them on their merits as they apply to your needs. Even if you decide polars doesn’t meet your needs it is good to evaluate options and learn along the way. Hopefully this article will get you started down that path.
Polars
As mentioned above, pandas has been the data analysis tool for python for the past few years. Wes McKinney started the initial work on pandas in 2008 and the 1.0 release was in January 2020. Pandas has been around a long time and will continue to be.
While pandas is great, it has it’s warts. Wes McKinney wrote about several of these challenges. There are many other criticisms online but most will boil down to two items: performance and awkward/complex API.
Polars was initially developed by Richie Vink to solve these issues. His 2021 blog post does a thorough job of laying out metrics to back up his claims on the performance improvements and underlying design that leads to these benefit with polars.
The user guide concisely lays out the polars philosophy:
The goal of Polars is to provide a lightning fast DataFrame library that:
- Utilizes all available cores on your machine.
- Optimizes queries to reduce unneeded work/memory allocations.
- Handles datasets much larger than your available RAM.
- Has an API that is consistent and predictable.
- Has a strict schema (data-types should be known before running the query).
Polars is written in Rust which gives it C/C++ performance and allows it to fully control performance critical parts in a query engine.
As such Polars goes to great lengths to:
- Reduce redundant copies.
- Traverse memory cache efficiently.
- Minimize contention in parallelism.
- Process data in chunks.
- Reuse memory allocations.
Clearly performance is an important goal in the development of polars and key reason why you might consider using polars.
This article won’t discuss performance but will focus on the polars API. The main reason is that for the type of work I do, the data easily fits in RAM on a business-class laptop. The data will fit in Excel but it is slow and inefficient on a standard computer. I rarely find myself waiting on pandas once I have read in the data and have done basic data pre-processing.
Of course performance matters but it’s not everything. If you’re trying to make a choice between pandas, polars or other tools don’t make a choice based on general notions of “performance improvement” but based on what works for your specific needs.
Getting started
For this article, I’ll be using data from an earlier post which you can find on github.
I would recommend following the latest polar installation instructions in the user guide .
I chose to install polars with all of the dependencies:
python -m pip install polars[all]
Once installed, reading the downloaded Excel file is straightforward:
import polars as pl
df = pl.read_excel(
source="2018_Sales_Total_v2.xlsx", schema_overrides={"date": pl.Datetime}
)
When I read this specific file, I found that the date column did not come
through as a
DateTime
type so I used the
scheme_override
argument to make
sure the data was properly typed.
Since data typing is so important, here’s one quick way to check on it:
df.schema
OrderedDict([('account number', Int64),
('name', Utf8),
('sku', Utf8),
('quantity', Int64),
('unit price', Float64),
('ext price', Float64),
('date', Datetime(time_unit='us', time_zone=None))])
A lot of the standard pandas commands such as
head
,
tail
,
describe
work as expected with a little extra output sprinkled in:
df.head()
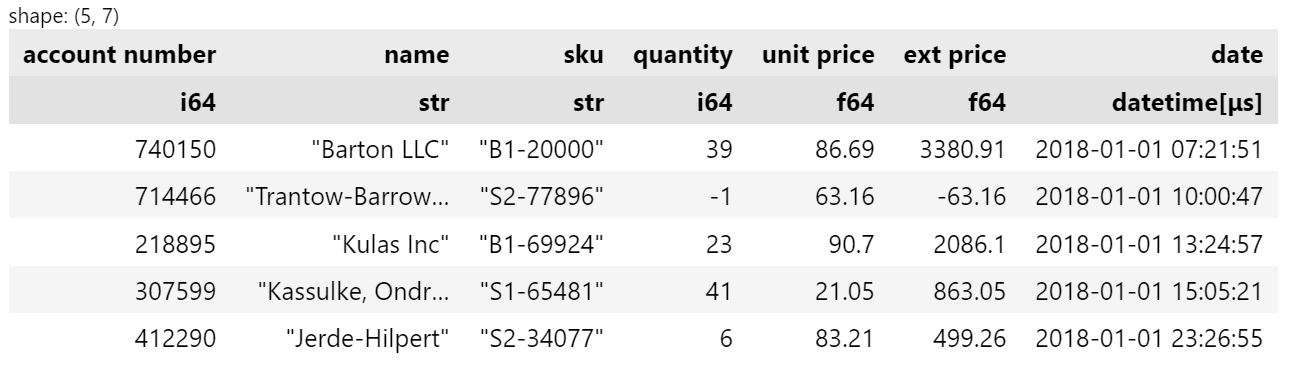
df.describe()
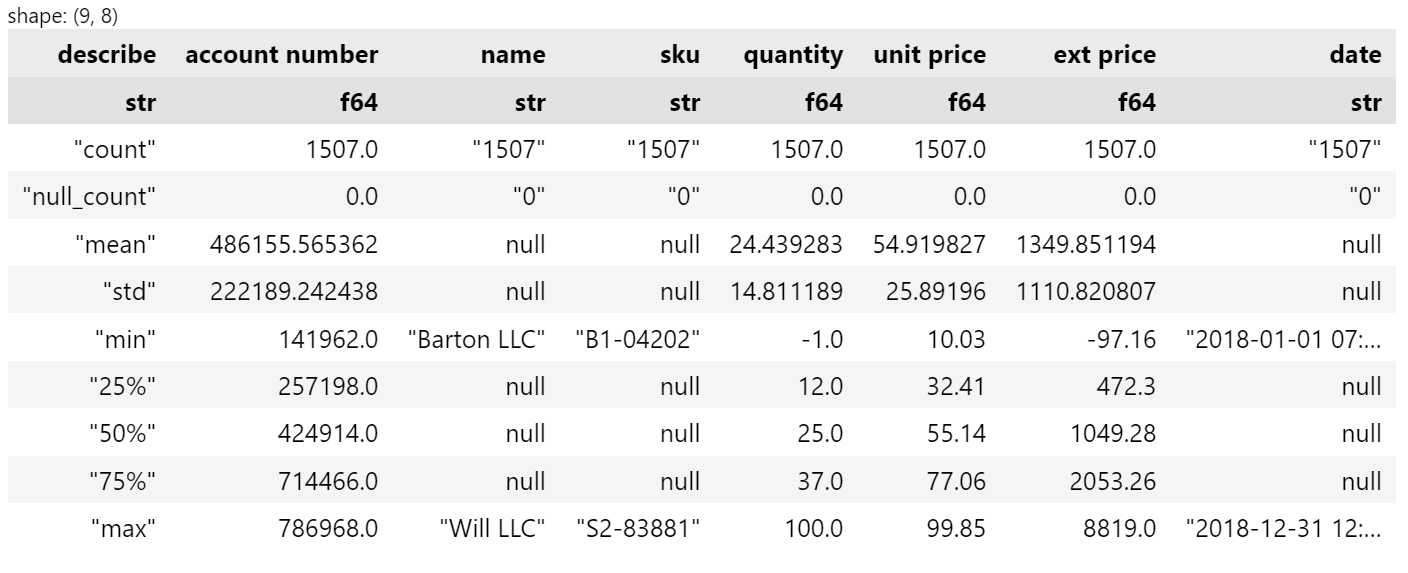
The polars output has a couple of notable features:
- The
shapeis included which is useful to make sure you’re not dropping rows or columns inadvertently - Underneath each column name is a data type which is another useful reminder
- There are no index numbers
- The string columns include ” ” around the values
Overall, I like this output and do find it useful for analyzing the data and making sure the data is stored in the way I expect.
Basic concepts - selecting and filtering rows and columns
Polars introduces the concept of Expressions to help you work with your data. There are four main expressions you need to understand when working with data in polars:
selectto choose the subset of columns you want to work withfilterto choose the subset of rows you want to work withwith_columnsto create new columnsgroup_byto group data together
Choosing or reordering columns is straightforward with
select()
df.select(pl.col("name", "quantity", "sku"))
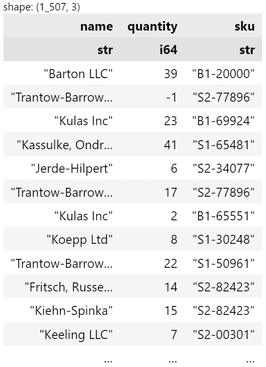
The
pl.col()
code is used to create column expressions. You will want to use this
any time you want to specify one or more columns for an action. There are shortcuts where
you can use data without specifying
pl.col()
but I’m choosing to show the recommended way.
Filtering is a similar process (note the use of
pl.col()
again):
df.filter(pl.col("quantity") > 50)
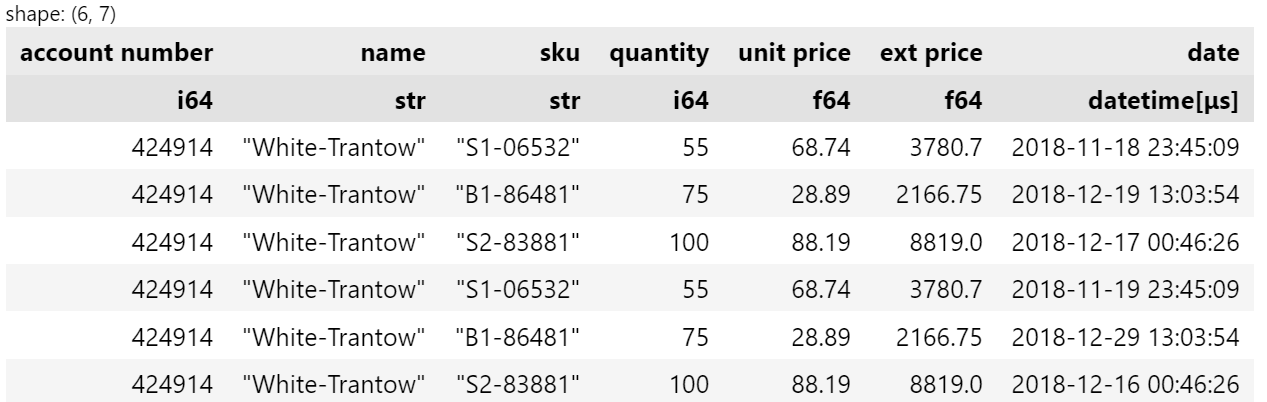
Coming from pandas, I found selecting columns and filtering rows to be intuitive.
Basic concepts - adding columns
The next expression,
with_columns
, takes a little more getting used to. The easiest way
to think about it is that any time you want to add a new column to your data, you need to
use
with_columns
.
To illustrate, I will add a month name column which will also show how to work with date and strings.
df.with_columns((pl.col("date").dt.strftime("%b").alias("month_name")))
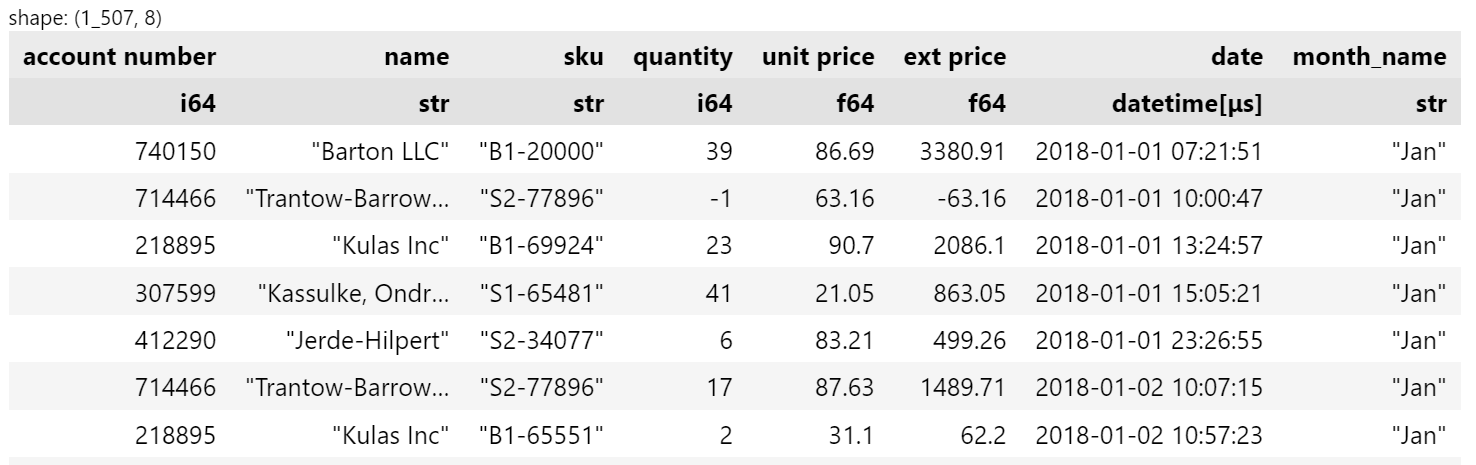
This command does a couple of things to create a new column:
- Select the
datecolumn - Access the underlying date with
dtand convert it to the 3 character month name usingstrftime - Name the newly created column
month_nameusing thealiasfunction
As a brief aside, I like using
alias
to rename columns. As I played with polars,
this made a lot of sense to me.
Here’s another example to drive the point home.
Let’s say we want to understand how much any one product order contributes to the total percentage unit volume for the year:
df.with_columns(
(pl.col("quantity") / pl.col("quantity").sum()).alias("pct_total")
)
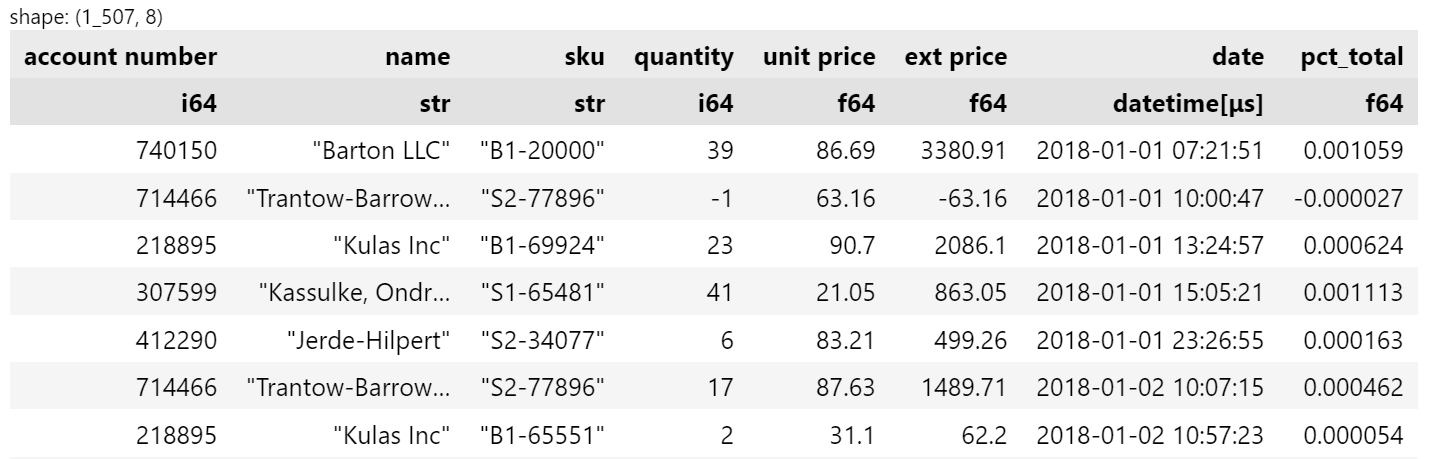
In this example we divide the line item quantity by the total quantity
pl.col("quantity").sum()
and label it as
pct_total
.
You may have noticed that the previous
month_name
column is not there. That’s because
none of the operations we have done are in-place. If we want to persist a new column,
we need to assign it to a new variable. I will do so in a moment.
I briefly mentioned working with strings but here’s another example.
Let’s say that any of the sku data with an “S” at the front is a special product and we want to
indicate that for each item. We use
str
in a way very similar to the pandas
str
accessor.
df.with_columns(pl.col("sku").str.starts_with("S").alias("special"))
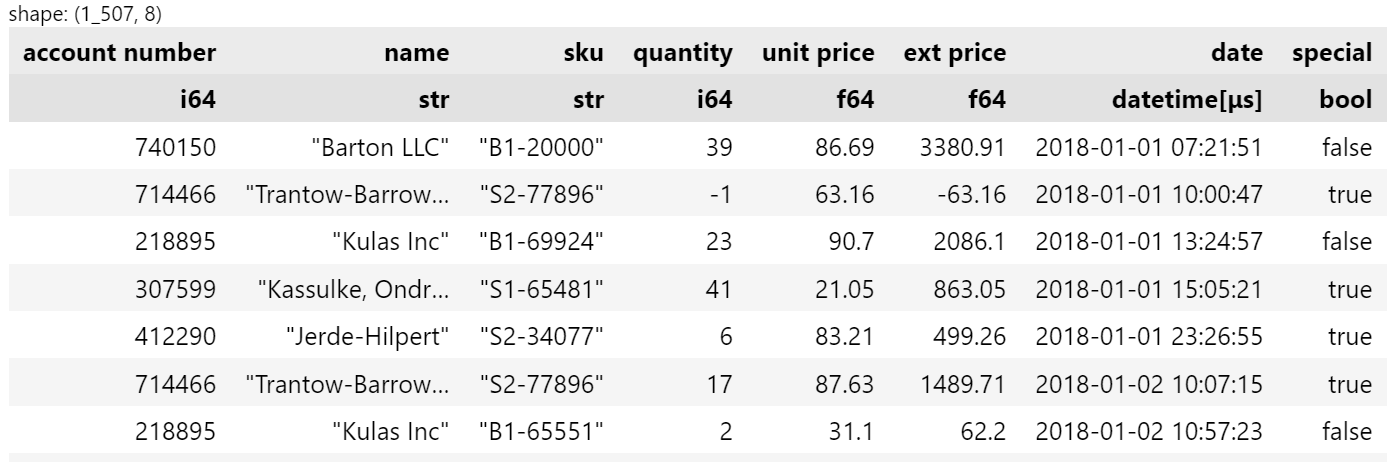
Polars has a useful function
when
then
otherwise
which can replace
pandas
mask
or
np.where
Let’s say we want to create a column that indicates a special or includes the original sku if it’s not a special product.
df.with_columns(
pl.when(pl.col("sku").str.starts_with("S"))
.then(pl.lit("Special"))
.otherwise(pl.col("sku"))
.alias("sales_status")
)
Which yields:
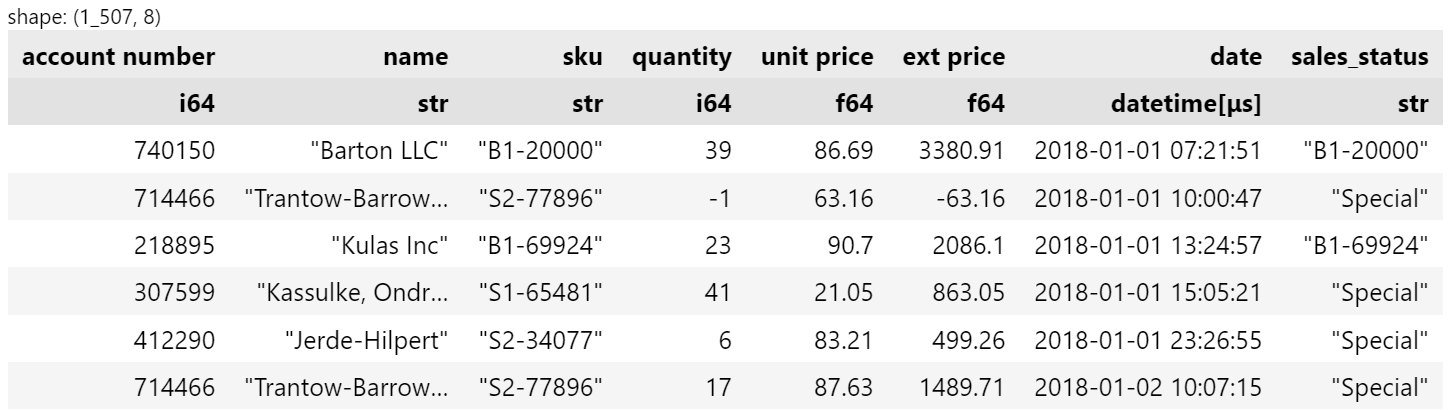
This is somewhat analogous to an if-then-else statement in python. I personally like this syntax because I alway struggle to use pandas equivalents.
This example also introduces
pl.lit()
which we use to assign a literal value to
the columns.
Basic concepts - grouping data
The pandas
groupby
and polars
group_by
functional similarly but the key
difference is that polars does not have the concept of an index or multi-index.
There are pros and cons to this approach which I will briefly touch on later in this article.
Here’s a simple polars
group_by
example to total the unit amount by sku by customer.
df.group_by("name", "sku").agg(pl.col("quantity").sum().alias("qty-total"))
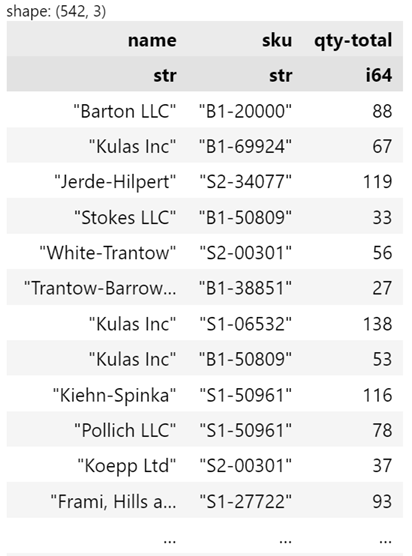
The syntax is similar to pandas
groupby
with
agg
dictionary approach I
have mentioned before. You will notice that we continue to use
pl.col()
to
reference our column of data and then
alias()
to assign a custom name.
The other big change here is that the data does not have a multi-index, the result is
roughly the same as using
as_index=False
with a pandas groupby. The benefit of this
approach is that it is easy to work with this data without flattening or resetting your data.
The downside is that you can not use
unstack
and
stack
to make the data
wider or narrower as needed.
When working with date/time data, you can group data similar to the pandas grouper function
by using
group_by_dynamic
:
df.sort(by="date").group_by_dynamic("date", every="1mo").agg(
pl.col("quantity").sum().alias("qty-total-month")
)
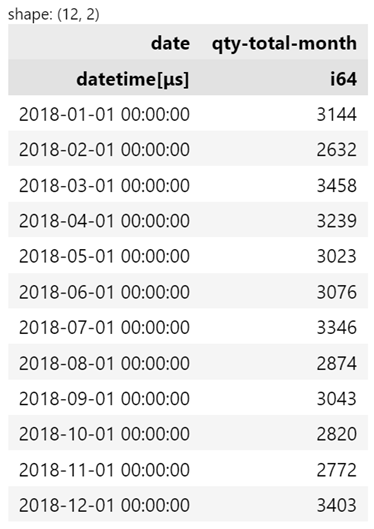
There are a couple items to note:
- Polars asks that you sort the data by column before doing the
group_by_dynamic - The
everyargument allows you to specify what date/time level to aggregate to
To expand on this example, what if we wanted to show the month name and year, instead of the
date time? We can chain together the
group_by_dynamic
and add a new column by using
with_columns
df.sort(by="date").group_by_dynamic("date", every="1mo").agg(
pl.col("quantity").sum().alias("qty-total-month")
).with_columns(pl.col("date").dt.strftime("%b-%Y").alias("month_name")).select(
pl.col("month_name", "qty-total-month")
)
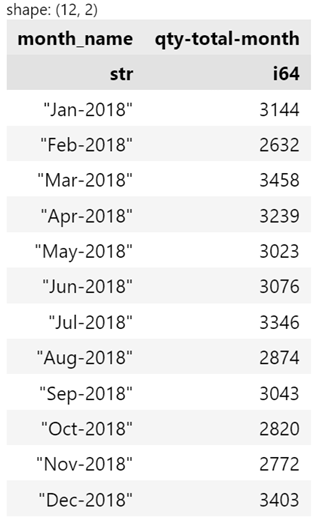
This example starts to show the API expressiveness of polars. Once you understand the basic concepts, you can chain them together in a way that is generally more straightforward than doing so with pandas.
To summarize this example:
- Grouped the data by month
- Totaled the quantity and assigned the column name to
qty-total-month - Change the date label to be more readable and assigned the name
month_name - Then down-selected to show the two columns I wanted to focus on
Chaining expressions
We have touched on chaining expressions but I wanted to give one full example below to act as a reference.
Combining multiple expressions is available in pandas but it’s not required. This post from Tom Augspurger shows a nice example of how to use different pandas functions to chain operations together. This is also a common topic that Matt Harrison (@__mharrison__) discusses.
Chaining expressions together is a first class citizen in polars so it is intuitive and an essential part of working with polars.
Here is an example combining several concepts we showed earlier in the article:
df_month = df.with_columns(
(pl.col("date").dt.month().alias("month")),
(pl.col("date").dt.strftime("%b").alias("month_name")),
(pl.col("quantity") / pl.col("quantity").sum()).alias("pct_total"),
(
pl.when(pl.col("sku").str.starts_with("S"))
.then(pl.lit("Special"))
.otherwise(pl.col("sku"))
.alias("sales_status")
),
).select(
pl.col(
"name", "quantity", "sku", "month", "month_name", "sales_status", "pct_total"
)
)
df_month
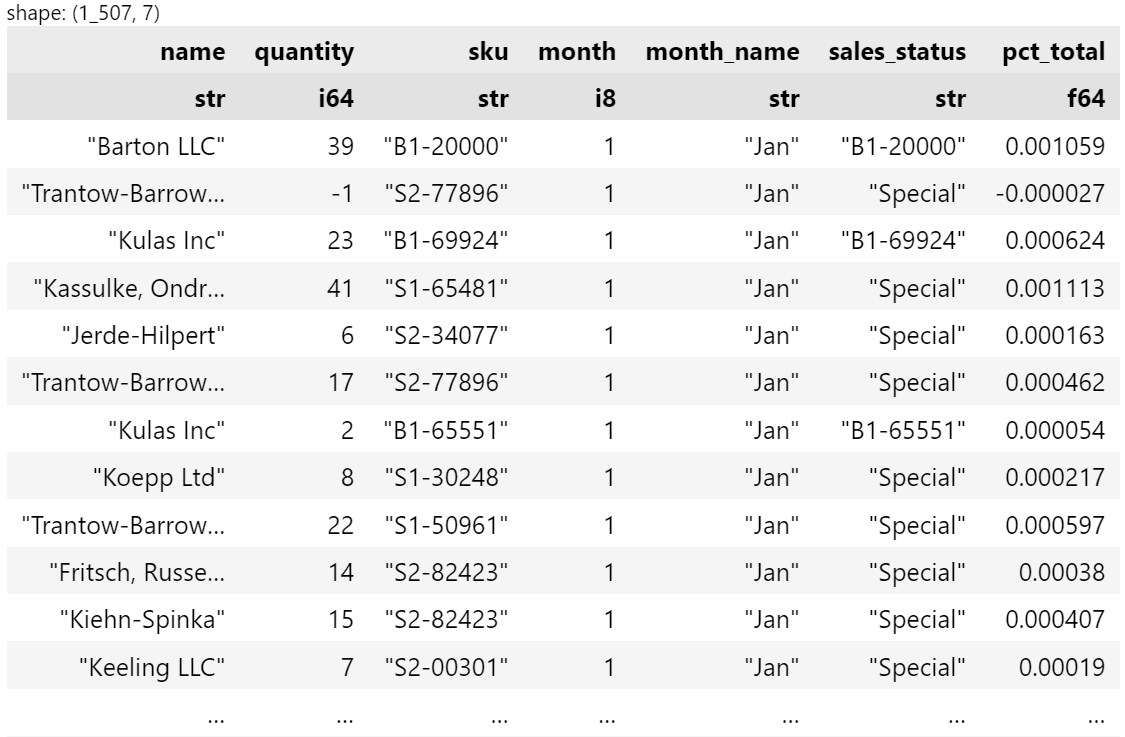
I made this graphic to show how the pieces of code interact with each other:
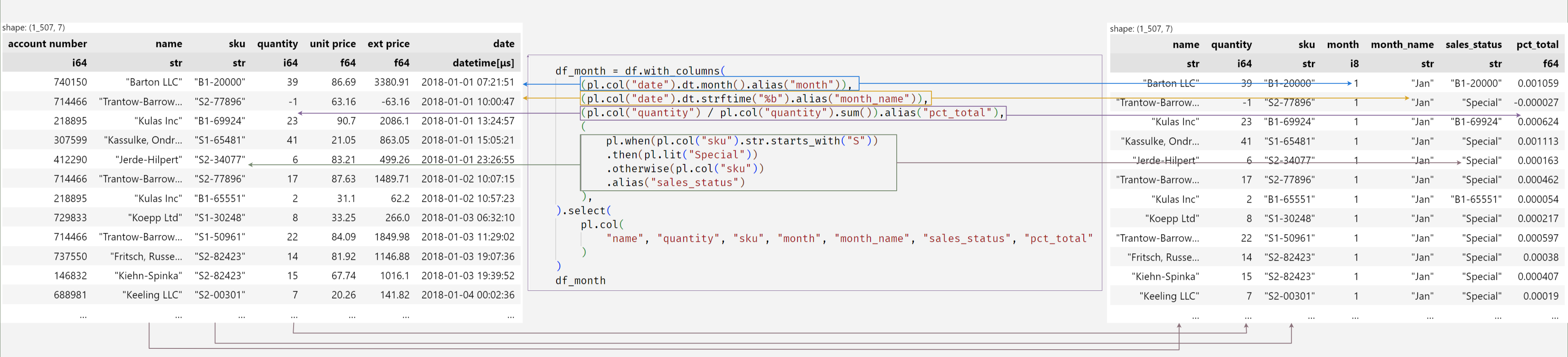
The image is small on the blog but if you open it in a new window, it should be more legible.
It may take a little time to wrap your head around this approach to programming. But the results should pay off in more maintainable and performant code.
Additional notes
As you work with pandas and polars there are convenience functions for moving back and forth between the two. Here’s an example of creating a pandas dataframe from polars:
df.with_columns(
pl.when(pl.col("sku").str.starts_with("S"))
.then(pl.lit("Special"))
.otherwise(pl.lit("Standard"))
.alias("sales_status")
).to_pandas()
Having this capability means you can gradually start to use polars and go back to pandas if there are activities you need in polars that don’t quite work as expected.
If you need to work the other way, you can convert a pandas dataframe to a polars one using
from_pandas()
Finally, one other item I noticed when working with polars is that there are some nice
convenience features when saving your polars dataframe to Excel. By default the dataframe
is stored in a table and you can make a lot of changes to the output by tweaking the
parameters to the
write_excel()
. I recommend reviewing the official API docs for the details.
To give you a quick flavor, here is an example of some simple configuration:
df.group_by("name", "sku").agg(pl.col("quantity").sum().alias("qty-total")).write_excel(
"sample.xlsx",
table_style={
"style": "Table Style Medium 2",
},
autofit=True,
sheet_zoom=150,
)
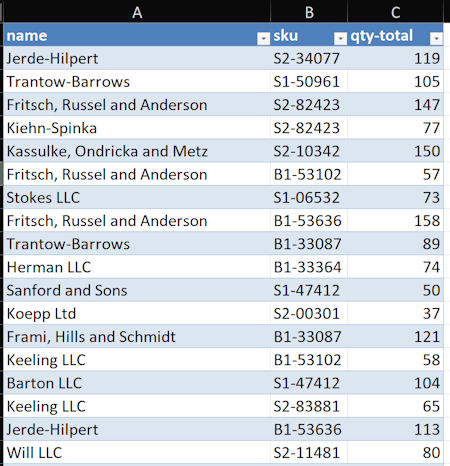
There are a lot of configuration options available but I generally find this default output easier to work with thank pandas.
Additional resources
I have only touched on the bare minimum of capabilities in polars. If there is interest, I’ll write some more. In the meantime, I recommend you check out the following resources:
- Official user guide
- Modern Polars from Kevin Heavey
The Modern Polars resource goes into a much more detailed look at how to work with pandas and polars with code examples side by side. It’s a top notch resource. You should definitely check it out.
Conclusion
Pandas has been the go-to data analysis tool in the python ecosystem for over a decade. Over that time it has grown and evolved and the surrounding ecosystem has changed. As a result some of the core parts of pandas might be showing their age.
Polars brings a new approach to working with data. It is still in the early phases of its development but I am impressed with how far it has come in the first few years. As of this writing, polars is moving to a 1.0 release. This milestone means that the there will be fewer breaking changes going forward and the API will stabilize. It’s a good time to jump in and learn more for yourself.
I’ve only spent a few hours with polars so I’m still developing my long-term view on where it fits. Here are a few of my initial observations:
Polars pros:
- Performant design from the ground up which maximizes modern hardware and minimizes memory usage
- Clean, consistent and expressive API for chaining methods
- Not having indices simplifies many cases
- Useful improvement in displaying output, saving excel files, etc.
- Good API and user documentation
- No built in plotting library.
Regarding the plotting functionality, I think it’s better to use the available ones than
try to include in polars. There is a
plot
namespace in polars but it defers to
other libraries to do the plotting.
Polars cons:
- Still newer code base with breaking API changes
- Not as much third party documentation
- Not as seamlessly integrated with other libraries (although it is improving)
- Some pandas functions like stacking and unstacking are not as mature in polars
Pandas pros:
- Tried and tested code base that has been improved significantly over the years
- The multi-index support provides helpful shortcuts for re-shaping data
- Strong integrations with the rest of the python data ecosystem
- Good official documentation as well as lots of 3rd party sources for tips and tricks
Pandas cons:
- Some cruft in the API design. There’s more than one way to do things in many cases.
- Performance for large data sets can get bogged down
This is not necessarily exhaustive but I think hits the highlights. At the end of the day, diversity in tools and approaches is helpful. I intend to continue evaluating the integration of polars into my analysis - especially in cases where performance becomes an issue or the pandas code gets too be too messy. However, I don’t think pandas is going away any time soon and I continue to be excited about pandas evolution.
I hope this article helps you get started. As always, if you have experiences, thoughts or comments on the article, let me know below.
Comments