Intro to pdvega - Plotting for Pandas using Vega-Lite
Posted by Chris Moffitt in articles

Introduction
Much has been made about the multitude of options for visualizing data in python. Jake VanderPlas covered this topic in his PyCon 2017 talk and the landscape has probably gotten even more confusing in the year since this talk was presented.
Jake is also one of the creators of Altair (discussed in this post) and is back with another plotting library called pdvega. This library leverages some of the concepts introduced in Altair but seeks to tackle a smaller subset of visualization problems. This article will go through a couple examples of using pdvega and compare it to the basic capabilities present in pandas today.
pdvega
Likely sensing the inevitable questions about another plotting library, the pdvega documentation quickly gets to the point about its goals:
pdvega is a library that allows you to quickly create interactive Vega-Lite plots from Pandas dataframes, using an API that is nearly identical to Pandas’ built-in visualization tools, and designed for easy use within the Jupyter notebook.
The basic idea is that pdvega can improve on pandas plot output by adding more interactivity, improving the visual appeal and supporting the declarative Vega-Lite standard. The other nice aspect is that pdvega tries to leverage the existing pandas API so that it is relatively simple to get up and running and produce useful visualizations - especially in the Jupyter notebook environment.
plotting
For this example, I decided to use data from FiveThirtyEight’s Ultimate Halloween Candy Power Ranking post. FiveThirtyEight is gracious enough to make all of its data available here. If you are interested in finding fun data sets to analyze, I encourage you to check it out.
All of the code is meant to be run in a notebook. An example one is available on github.
Make sure the code is installed properly:
pip install pdvega
jupyter nbextension install --sys-prefix --py vega3
Get started by importing pandas and pdvega and reading the csv into a dataframe:
import pandas as pd
import pdvega
df = pd.read_csv("https://github.com/fivethirtyeight/data/blob/master/candy-power-ranking/candy-data.csv?raw=True")
Here’s what the data looks like:
| competitorname | chocolate | fruity | caramel | peanutyalmondy | nougat | crispedricewafer | hard | bar | pluribus | sugarpercent | pricepercent | winpercent | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100 Grand | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0.732 | 0.860 | 66.971725 |
| 1 | 3 Musketeers | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0.604 | 0.511 | 67.602936 |
| 2 | One dime | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.011 | 0.116 | 32.261086 |
| 3 | One quarter | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.011 | 0.511 | 46.116505 |
| 4 | Air Heads | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.906 | 0.511 | 52.341465 |
The data includes voter results on which one of 86 candy options was their favorite.
The
winpercent
column includes how often that candy was the vote winner.
The other columns include descriptive characteristics of that candy. The good folks
at FiveThirtyEight did lots of analysis, but we’ll do some quick EDA to compare stock pandas plotting
vs pdvega.
First, let’s look at the distribution of winning percentages using a histogram.
In pandas:
df["winpercent"].plot.hist()

Now in pdvega:
df["winpercent"].vgplot.hist()

There are a couple of key points here:
- The pdvega API is pretty much the same as pandas plotting. Instead of calling
plotyou can callvgplot. - The actual output looks much cleaner in pdvega
- The png shown here does not replicated the interactivity you get in a notebook
If we want to plot multiple distributions to look at the sugar and price percentiles, it’s fairly simple:
df[["sugarpercent", "pricepercent"]].plot.hist(alpha=0.5)
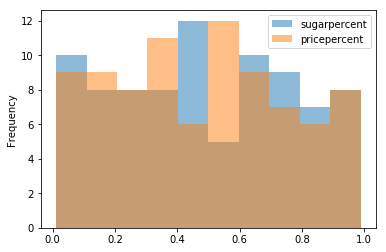
In pdvega, the syntax is a little cleaner because the
alpha
parameter is
not needed.
df[["sugarpercent", "pricepercent"]].vgplot.hist()
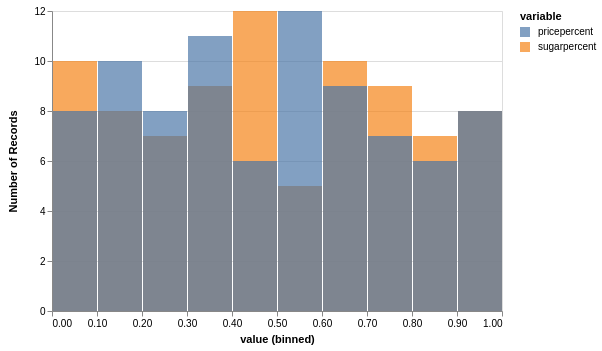
pdvega supports most of the standard plot types you would expect. Here’s an example of a horizontal bar chart showing the top 15 winpercentages. This fits in seamlessly with the standard pandas approach of sorting and viewing the top entries:
df.sort_values(by=['winpercent'], ascending=False).head(15).vgplot.barh(x='competitorname', y='winpercent')
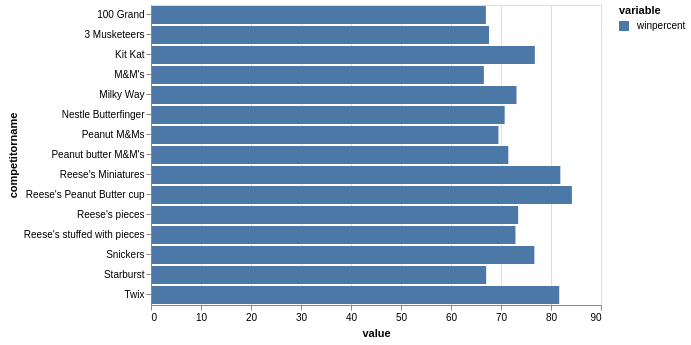
The one challenge I had was figuring out how to make sure the bars were ordered by winpercent not alphabetically but the name. I’m sure there is a way but I could not figure it out.
If we’re interested in looking at a more complicated analysis, the scatter plotting
functionality allows us to control the size and color of the plots based on the values
in a column. For instance, if we want to look at the relationship between winning percentages,
sugar percentiles, pricing percentiles and candy bar status, we can encode that
all in a single
vgplot.scatter
call:
df.vgplot.scatter(x='winpercent', y='sugarpercent', s='pricepercent', c='bar')
Once again, the API is similar to panda’s scatter plot but it natively creates
a more useful plot without additional tinkering. The ability to easily
encode the size of the plot using the
s
argument for size and
c
for color
is a simple enhancement that makes scatter plots much more useful.
Finally, pdvega supports statistical visualization with
pdvega.plotting.
A scatter matrix can be a useful tool to view multiple variable interactions
in one chart:
pdvega.scatter_matrix(df[["sugarpercent", "winpercent", "pricepercent"]], "winpercent")

This API is slightly different in that you pass the actual dataframe to the pdvega function but the basic approach is similar to the rest of the pdvega API. The individual plots are linked together so that zooming in one, interacts with the other plot.
Closing Thoughts
There is no doubt that the python visualization landscape is crowded. However, there is a lot of activity in this space and many powerful tools available. In the end, I think the competition is good but hope that some standards eventually emerge so that new users have a simpler time figuring out which tool is best for them. It’s always a concern in the open source world when resources get spread too thin across competing projects and the barrier for new users to learn is high.
That being said, pdvega is very early in its lifecycle but it shows promise. Some of the primary benefits are that it is easy to pick up, generates very nice visualizations out of the box and is primarily developed by Jake VanderPlas who is extremely active in this space and wants to drive some convergence of solutions. In addition, the library should see improvements in functionality as more people use it and generate feedback. I look forward to seeing how it grows and develops in future releases and where it ultimately lands in the crowded visualization space.
Comments